Kafka services: data ingestion and event streaming implementation.
Achieving high-performance real-time* data pipelines and event streaming all starts with Apache Kafka®.
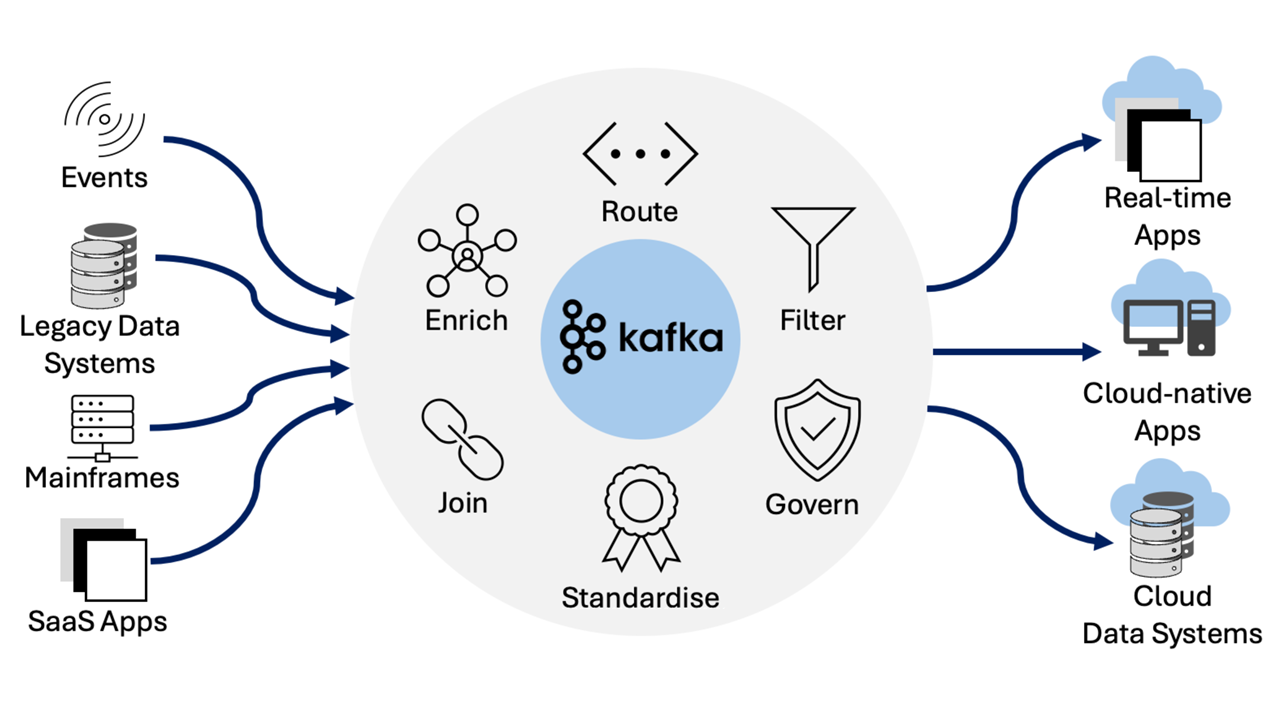
Apache Kafka is an open-source distributed streaming system used for stream processing, real-time* data pipelines, and data integration at scale.
Originally created at LinkedIn in 2011, Kafka is now used by thousands of companies globally including Manufacturers, Banks, Insurers, Airlines, Telcos and more.
Kafka has quickly evolved from a messaging que to a fully-fledge event streaming platform capable of handling over 1 million messages per second, or trillions of messages per day.
- Kafka unlocks powerful, event-driven programming for virtually any infrastructure.
- Build real-time*, data-driven apps and make complex back-end systems simple.
- Process, store, and connect your apps and systems with real-time* data.
How 4impact and Kafka can help with data streaming challenges
4impact amplifies the value of Kafka to provide a unified, high-throughput, low-latency platform for handling real-time* data feeds.
We provide an end-to-end service with a focus on reducing time to market and controlling customer's costs and risk, through an iterative and progressive delivery approach.
*Real-time is used as a referencable capability for Apache Kafka handling high-velocity and high-volume data, delivering thousands of messages per second with latencies as low as 2ms. KAFKA is a registered trademark of The Apache Software Foundation. 4impact has no affiliation with and is not endorsed by The Apache Software Foundation.
No matter your industry, Kafka enables deep data insights for the 'now' and the 'past'.
Manufacturers, Banks, Insurers, Airlines, Telcos and more can all harness the power of messaging, stream processing, storage and analysis of both historical and real-time data.
Capable of handling high-velocity and high-volume data, delivering thousands of messages per second.
LOW LATENCY
Can deliver a high volume of messages using a cluster of machines with latencies as low as 2ms.
PERMANENT STORAGE
Safely, securely store streams of data in a distributed, durable, reliable, fault-tolerant cluster.
HIGH SCALABILITY
Scale Kafka clusters up to a thousand brokers, trillions of messages per day, petabytes of data, hundreds of thousands of partitions. Elastically expand and contract storage and processing.
HIGH AVAILABILITY
Extend clusters efficiently over availability zones or connect clusters across geographic regions, making Kafka highly available and fault tolerant with no risk of data loss.